

画像中の文字を読み取ってデータ化してくれるOCRソフト、便利ですよね。
でも、
「無料のものは精度がちょっと・・・」
「そんなに使わないから有料のものを導入するのも・・・」
「持ってるんだけど日本語と英語にしか対応してなかった。原稿は中国語なのに」
などなど、いろんな不満があると思います。
(最後の残念な人は私です)
今日はそんなお悩みをまとめて解決してくれる、
「Googleドライブで原稿を保存→Googleドキュメントで開いてテキスト化」
という、お手軽かつ強力なOCRの方法をご紹介します。
OCR化の方法
作業はとても簡単です。
Googleドライブをお持ちでなければ、公式サイトからアクセスする必要があります。
GoogleドライブはGoogleの提供するオンラインのストレージサービスです。
15GBまでは無料で使えますので、
文書データがメインであれば基本的に容量を気にせずに使えます。
OCR化の作業の手順は・・・
- Googleドライブに保存したファイルを右クリック
- 「アプリで開く」を選択
- 「Googleドキュメント」を選択
これだけです!
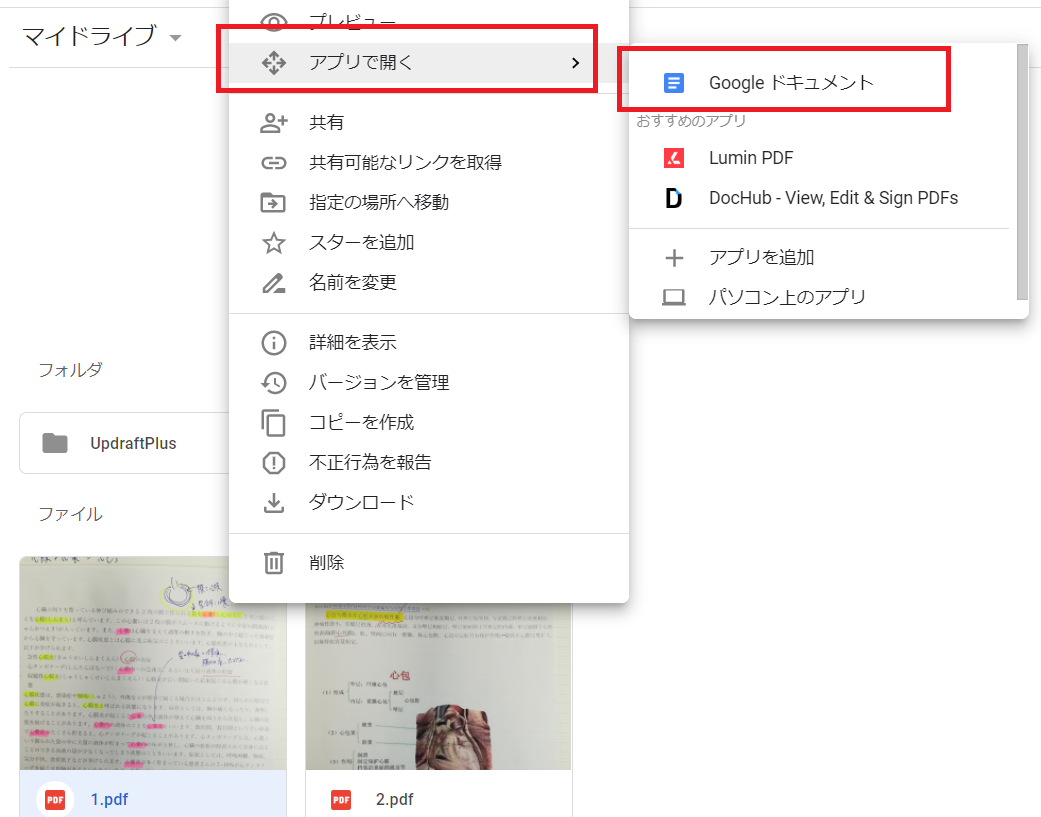
この後、自動的にGoogleドキュメントが開きます。
するとそこにはOCR化された、コピペできる状態のテキストが完成しています。
上の画像では、一旦pdfにした画像ファイル(jpgファイル)を使っていますが、jpgのままでも読み取れます。
精度はどのくらい?
さて、気になる精度はいかがでしょうか。
原稿を変えて、いくつか実験をしてみました。
ある程度きれいな原稿の場合
プリントアウトしたものをスキャナで読み取ってpdf化したような原稿の場合、
ほぼ100%、きれいに読み取ってくれます。
そこにマーキングされていたり、少しメモ書きがあってもです。
(手書き部分は正確に読み取られないと思った方がよいです)
スマホで撮影した画像データをそのままでも、誤認識はありますがかなりの精度で読み取ります。
私は今中国語を含む画像データをOCR化することが多いのですが、中国語でも問題ありません。
こちらが「ある程度きれいな画像」として用意した中国語テキストです。

OCR処理したテキスト(一部)はこちらです。
昌公編)最新医学大辞典(医菌藥出版株式会社)、《丁夕丁了力心 定冷詞辞典》(南山堂第6版)、《今日)治療藥 2011》(南江堂)、《工 山二力国際大百科事典》(ZD夕二力·十八y)等权威资料。从 而使本词典的编写更加填密、规范,并且可以找到出典和根据。《汉日医学大词典》(第2版)共载词条 29万余条,对汉口医学大词曲(第1版)14万余词条逐条进行了大幅度的修订和完善,新增15万余 词条。
Googleドキュメントでの原稿はこんな感じです。

上から2、3行目に日本語が一部混ざっているのをどう処理するのかな、と思っていたのですが、やはりちょっと厳しかったようで日本語は文字化けしてしまっています。
そのほかはいくつか誤認識はありますが、チェックをして十分使えるレベルです。
かなりぐちゃぐちゃな原稿の場合
では、一体どの程度まで読み取ってくれるのだろう。
そんな疑問、というか好奇心が湧いてきまして、少し実験をしてみました。
実験材料は、こちらのノートの1ページです。
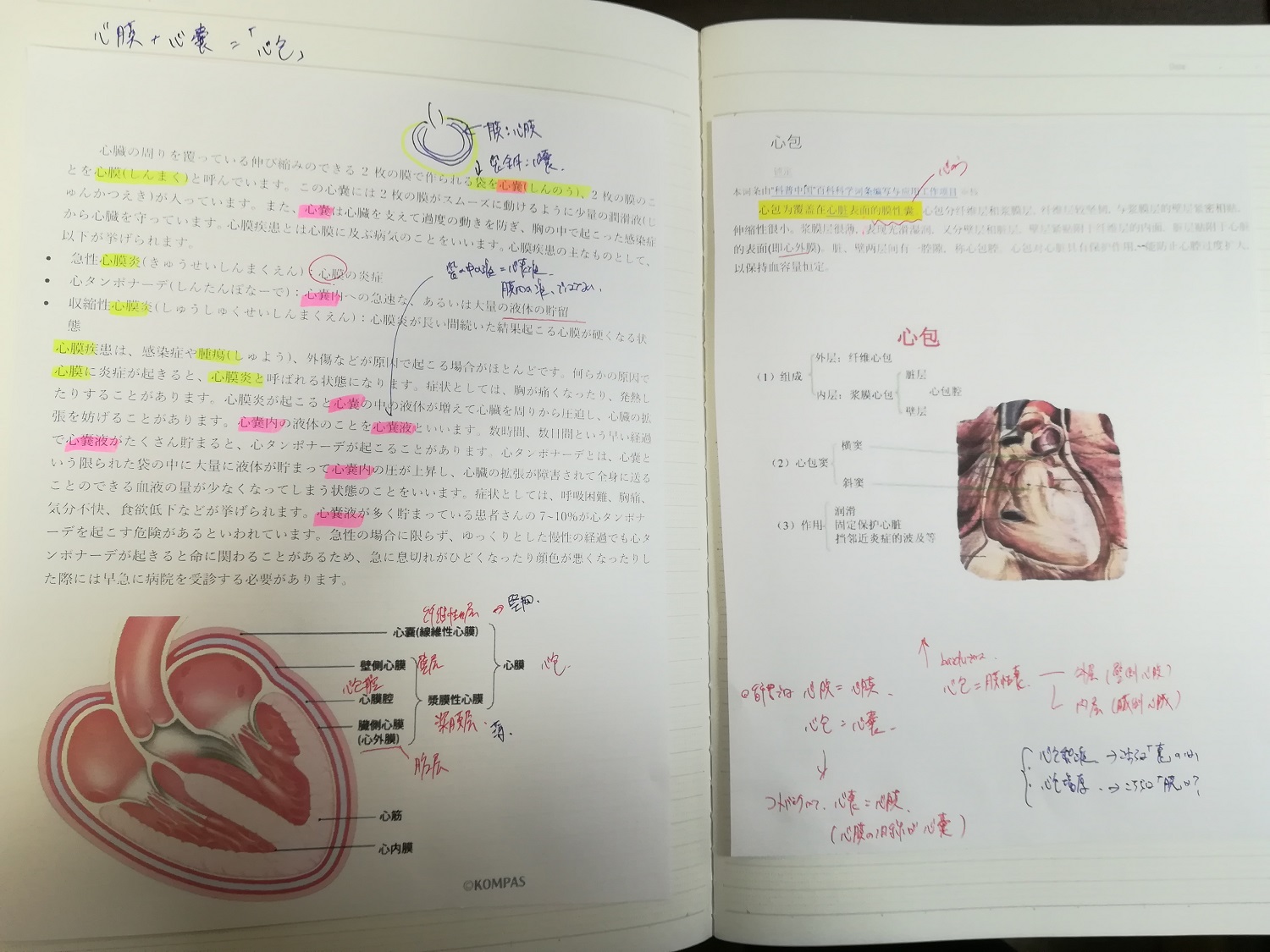
書き込みあり、マーキングあり。
おまけに「トナー交換」のサインがでてから2,3日経過しているので文字も薄い。
こんな「OCR泣かせ」な素材でどこまでやってくれるのか?
さすがに見開きは厳しかったようなので、
左側(日本語)と右側(中国語)で分けてスマホで撮影し、OCR処理しました。
日本語版の、Googleドキュメントで生成された状態(一部)です。

上の一部をコピペしたものです。
心脳の周りを覆っている仲び縮みのできる2枚の膜で作られる袋を心葉(しんのう)、2枚の際のご とを心膜(しんまく)と呼んでいます。この心意には2枚の吸がスムーズに動けるように少量の潤滑なし 一ゅんかつえき)が入っています。また、心葉は心臓を支えて過度の動きを防ぎ、胸の中で起こった感れたから心臓を守っています。心膜疾患とは心膜に及ぶ病気のことをいいます。心膜疾患の主なものとして 以下が挙げられます。
元のテキスト(慶應義塾大学病院HPより)はこちらです。
心臓の周りを覆っている伸び縮みのできる2枚の膜で作られる袋を心嚢(しんのう)、2枚の膜のことを心膜(しんまく)と呼んでいます。この心嚢には2枚の膜がスムーズに動けるように少量の潤滑液(じゅんかつえき)が入っています。また、心嚢は心臓を支えて過度の動きを防ぎ、胸の中で起こった感染症から心臓を守っています。心膜疾患とは心膜に及ぶ病気のことをいいます。心膜疾患の主なものとして、以下が挙げられます。
どうでしょう。
人によって「使える・使えない」の判断は微妙なところかもしれません。
そして、中国語の方はというと。
こちらは始めに元データをお見せします。
元データ(百度百科:心包より)
心包为覆盖在心脏表面的膜性囊。心包分纤维层和浆膜层,纤维层较坚韧,与浆膜层的壁层紧密相贴,伸缩性很小。浆膜层很薄,表现光滑湿润,又分壁层和脏层,壁层紧贴附于纤维层的内面,脏层贴附于心脏的表面(即心外膜)。脏、壁两层间有一腔隙,称心包腔。心包对心脏具有保护作用,能防止心腔过度扩大,以保持血容量恒定。
実は下の写真の状態からOCR化したら、全然うまくいきませんでした。
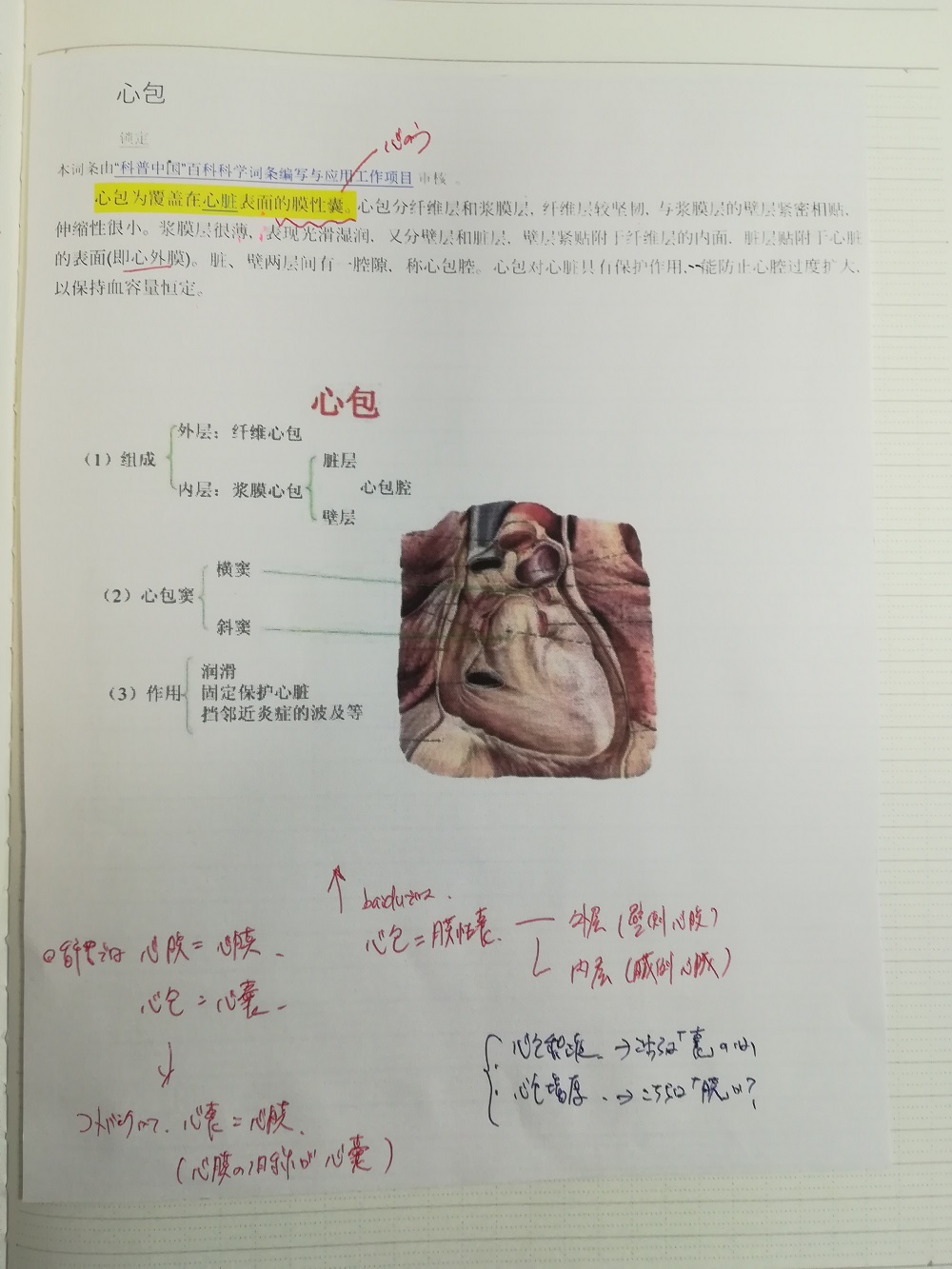
上の写真のOCR化です。ちょっとこれは厳しいですね。
心已为更在心上人的腹北、心包分排)和淡膜、「推」、较长团、于浆膜的) , 伸縮性很小。浆膜)、津、《龙背温润、又分层和脏,重紧贴的「」的內面,上、貼附「心」, 的表面(即心外膜)、山、壁两间有一腔隙、称心包腔、心包对心脏有保护作用是防止心脏过度打人、 以保持血容量走
もう少し近づいて、このくらいの状態にしてもう一度チャレンジしました。

再チャレンジの結果です。こちらはうまくいってます。
心包为覆盖在心脏表面的膜性囊。心包分纤维层和浆膜层,纤维较坚韧,与浆膜层的壁层紧密相贴, 伸缩性很小。浆膜层很薄,表现光滑湿润,又分離和方,壁层紧厂维层的门面,层點「心 的表面(即心外膜)。脏、壁两间有一腔隙,称心包腔。心包对心脏具有保护作用,能防止心胜过度扩大, 以保持血容量恒定。
このくらいの精度であれば、十分使えるのではないかな、と思います。
まとめ
GoogleドライブにOCR化したい画像データを保存して、
それをGoogleドキュメントで開くとOCR化されます。
GoogleドライブのOCRはかなり高機能です。
印刷して書き込み、マーキングしたものでもある程度正確に読み取ってくれます。
きれいな画像でないとOCR化できない、と諦めていた方。
ぜひ一度お試しください!








中国語のアプリで困っていましたがスクリーンショットをこの方法でgoogleドキュメントで開いたらテキストになり翻訳ソフトに掛けられました。
本当にありがとうございました。
kanecomさま
コメントありがとうございます!
お役にたててよかったです。
スクリーンショットなら鮮明なのできれいにテキスト化されそうですね。