Contents
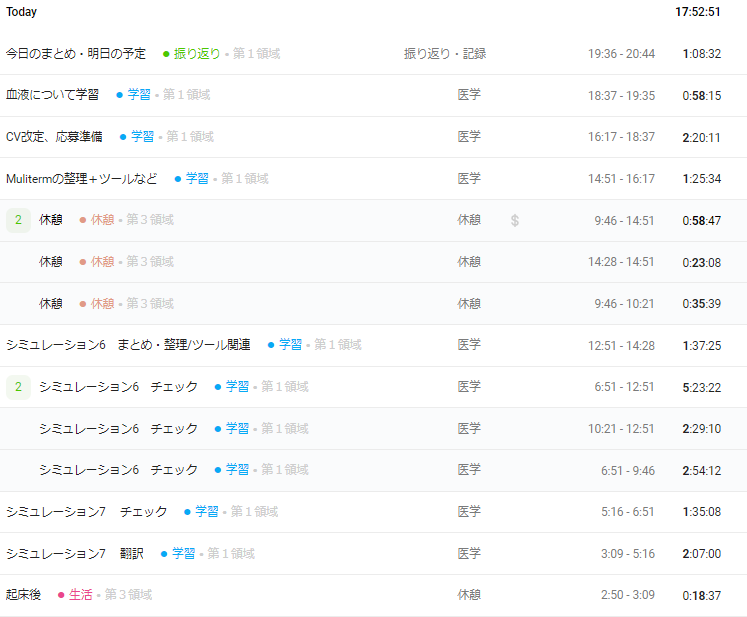
6/29の記録
- シミュレーション学習その6と7(チェックと翻訳)
- ツールの学習(チェックスキーム関連)
- トライアル応募準備(CVの改定)
- 血液について学習
今日も翻訳とチェックをしつつ、少しまたミス対策について考えました。
じっくり寝かせた結果
まずは昨日のログにて書いた、
チェックまでに違う翻訳案件を挟んだらどうなるか?の結果です。
翻訳中にかなり粘って調べたのですが適訳が見当たらず、「意味としては間違っていない」訳で終わらせたものがありました。
チェックの際にもう一度調べたらその適訳にあっさりたどり着けたのが一番の収穫です。
むしろ、「なぜそのときにたどりつけなかったのか」の分析が収穫というべきかもしれませんね。
たどり着けなかった言葉は、実はかなり普通に使われている言葉でした。
そして、全くたどり着くのが難しい言葉でも何でもなかったのです。
心機能に関する一文で、直訳すれば「左室拡張期の”順応性”の低下(左室舒张期顺应性减低)」という言葉です。
検索ワードまで残していなかったので当初どういう思考でいたのか不明なところもあるのですが、
順応性ってなんだろう。適応性?柔軟性?意味としては柔軟性がなくなって拡張期に膨らみにくくなるということだけど、順応性でも柔軟性でもそれらしいものが見当たらない・・・と探して、「柔軟性」と仮置きしていました。
適訳は「コンプライアンス」です(伸展性でもいいと思います)。
これですね、
中国語側からも普通に探せますし(「顺应性」で検索するだけでたどり着けます)、日本語でも例えば”左室拡張期 * 低下” でgoogle検索すればあっさり出ます。
普通の状態ならたどり着けるはずです。
なぜたどり着けなかったかと考えたら、やはり疲れのたまっている夜にやっていたからではないかと思います。
自分では集中できていると思っていたんですが、脳は疲れていて全然働いてなかったとうことですね。
もちろん、それ以前に「このくらいの単語は知っているのが普通」という知識不足の問題はあります。あとはそれこそ、思考の「柔軟性」が足りないという問題もあります。
対策としては、
夜なるべく翻訳しない、する場合は「訳質はいつもの3割引き」ぐらいに考えて、ミスはあるものとしてすっきりした朝などにチェックを行うようにします。
もしくは、ブドウ糖の補給をして頑張るかですね。
これ(これじゃなくても同じでしょうけど)、ものすごい速攻性ありますよ。
常備してます。
この時は、自分が疲れている認識がなかったので補給もしませんでしたけど・・・。
ここまで書いて思いました。
全然、根本的な対策ではないですねこれ。
もっとこう、「疲れていてもいつも同じように検索できるスキーム」こそが必要なんですよね。
すみません。もう少し考えます。
ミスを上流からせき止める作戦
チェックまで間を空けて、スキームを変えてもそれでも後工程にまで残るミスはまだあります。
どうしたものかな。
そこで思ったのは、「そもそも翻訳中のミスが減れば、後工程で対策するミスも減るはず」という当たり前のことです。
ということでいくつか対策を考えました。
まだ実際の運用はこれからのものもあります。
(1)OCRの読み取りミスを減らす
頂くお仕事は原稿がOCRで読み取りづらいpdfのことが多いです(これは翻訳対象の文書の性質上、仕方がないです)。
もちろんOCR化してからチェックはしているのですが、誤認識のままTradosへ組み込んでしまうこともありました。
そしてそれが原因でのミスも起こっていました。
以前ご紹介した、Google Driveを使った方法より精度のよいOCRソフトはないものか。
と思って有料、無料といくつか試したのですが、やはり今の所はGoogle様が最強という結論です。
なのでこれについては、当面現状維持です。
(2)ミスしやすい箇所などをマーキングしてからTradosへ組み込む
ミスしにくいように色をつけて組み込んだらどうだろうか。
これがテスト版として組み込んだ状態です。

赤が過去に間違えた単語、青が訳抜けしやすい単語、緑が注意を要する単語です。
黄色で読点がマーキングされているのは、中国語では「、」と日本語の読点に当たる「,」が異なる意味を持ち(「、」が並列の意味になります)、見落とすと誤訳につながるからです。
黄色蛍光ペンはワードの置換機能(置換-オプションで蛍光ペンを選択して置換)を使っています。
小さな「、」なんで、文字色を変えるよりもわかりやすいかなと思いました。
赤青緑は、一発で置換できるソフトを使っています。
もちろん秀丸のマクロでもなんでもよいとは思います。
こちらの記事のビデオセミナー1480号で紹介されてますよ、と書いたソフトです。
もしかしたら明日あたり、動画メルマガになってるかもしれませんが・・・。
特許翻訳の英語の時は、私は文字の強調表示設定をしている秀丸に一旦原文を移してそこでぶつ切りにしていたのですが、今回の中国語の案件は、文の区切りが短いのもあってTradosに直接打ち込んでいます。
色がついていればさすがに意識するんじゃないかと思っています。
次のシミュレーションの時に実際にやってみます。
(3)Tradosのメモリの「一致率の最小値」を上げる
これも次のシミュレーションの時にやることです。
短く区切って入れていると、メモリがヒットしやすいのですがその分当然似て非なるものまで部分マッチで拾ってきてしまいます。
これがミスを誘発していることはわかってはいたのですが、翻訳スピードを上げるという意味で手放し難く、そのままにしていました。
ただ、やはりここからのミスが多いです。
なので、今までデフォルト(70%)で使用していたのをまずは90%にして様子をみてみます。
ちなみに、一致率の最小値はプロジェクトの設定→言語ペア→翻訳メモリと自動翻訳で変更できます。

・・・と、がーっと書きましたが次にやることはざっとこんな感じです。
多分、いろいろまどろっこしいことをしているな、と思われるかもしれません。
実際にやってみて効果を実感できたら、またちゃんと記事にします。
6/30の予定
- 血液の学習をもう少し
- 次のシミュレーション学習
- 読みたい本を読む
時間の記録
学習時間:15h25m