

先月から、翻訳ミス撲滅のためにいろいろと試行錯誤してきました。
きっかけは、仕事を頂くようになってからチェックに時間をかけているにも関わらず、納品間際になってヒヤッとすることが続いたことです。
1件の重大事件の背後には29件の軽微な事故と、事故寸前の300件のヒヤッとした経験が隠れている、というヒヤリハットの法則がありますが、
このままではいつか「1」を引き当ててしまう。
特に何度も見ているはずなのに、最後まで出てくる「訳抜け」。
これをなくすにはどうしたらいいのか。
そんな気持ちから取り組んだ、この約3週間の結果を書き残しておきます。
Contents
目標、アプローチ、そして結果
●目標
翻訳ミス(特に訳抜け)を少なくすること
●アプローチ
- ミスの記録(どこで、どんな種類のミスをしたか。原文、当初訳文、正しい訳文、原因をエクセルにまとめる)
- チェックまで時間を空ける
- 訳抜けチェック工程を細分化(全体・逐語+内容の確認)
- EKWordsの活用
- ミスしやすい部分を色で強調表示したデータをTradosへ組み込む
- Tradosメモリの一致率の最小値を上げる
参考記事:
(1、3、4について)
6/26のログ:チェックの過程で自分が機械翻訳になってみた
(5、6について)
6/29のログ:ミスを上流からせき止める作戦
●結果
訳抜けミスは減りました。その他のミスも減少傾向にあります。
●特にお伝えしたいこと
- 色で強調表示はやはり強力です。
- EKWordsとJustRight!の機械的チェックも必須です。
データを読み解く
「減った」と言われましても・・・
一体、何パーセント減ったんですかということになりますよね。
データをお見せします。
その前にいくつかお断りです。
エクセルのミスデータベースは、6/26からの記録があり、計8件の案件分があります。
案件には実ジョブ、そして実ジョブと同条件にしたシミュレーション学習分を含みます。
ちょうど4件ずつ、色つき+Tradosのマッチ率を減らしたものと、そうでないものがあります。
6/26以前のデータはエクセルにまとめていない(知子の情報に入れたり、マインドマップにしたり)ので、全面的なデータではないですが、色つき+Tradosのマッチ率変更の対策の効果はわかるかなと思います。
ミスの定義ですが、チェックの過程で表記を変更したものを基本的に全て「ミス」として記録しています。
誤訳、訳抜けのほか、「誤訳とは言えないけれど表現を変えるべき」と思ったものも「表現」カテゴリーで記録しています。
では、まいります。
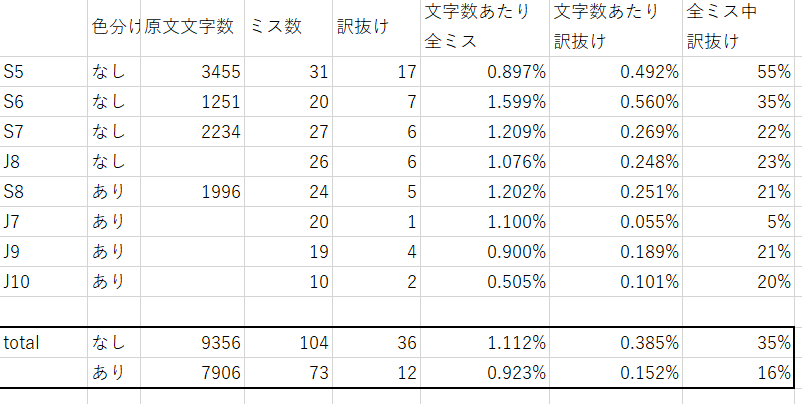
1.色つき+Tradosのマッチ率変更で訳抜けは減ったのか
こちらがデータです。
実ジョブ分についての文字数は、一応原文文字数を伏せましたがまあ計算したらわかってしまいますね。2000-2500文字程度というところです。
案件の難易度の差で一概に言えない部分は当然あるのですが、文字数あたりのミス数、訳抜けの割合を比較しました。
期間中全ミス:177件
●ここからわかること
- 全ミスの割合は対策前:1.1% 対策後:0.9%でそこまで変化がない。
- 訳抜けの割合は対策前:0.38% 対策後:0.15%で半減した。
訳抜け防止には効果があったと言えるでしょう。
実際、作業中にも効果を実感しました。
特に、色がついているとどうしても注意が向きます。
色をつけた部分の訳抜けはゼロです。
ただ、ミス自体は減っているとは言え、劇的な変化はないです。
訳抜けが減っているとしたら何かが増えていますね。何が増えているのでしょう。
ということで、次にミスの種類について見ていきます。
2. どんなミスが多いのか
データはこちらです。
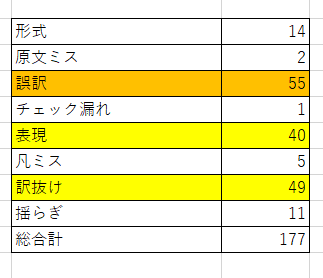
「訳抜け」には、いらない言葉がくっついている「訳多め」も含みます。(細分化して分けています)
思ったより、「誤訳」が多いと感じました。ここは訳抜け対策とは別のアプローチが必要なので今後の課題です。
「表現」は集計期間の後半にかけて多くなっています。これは、後半は翻訳スピードを上げようと、細かい所を後にして翻訳していた影響があるのではないかと思います。
訳抜けが減った分、増えたのはこの「表現」の部分でした。
形式は全角・半角の不統一、単位などのミスです。
3.どの段階でミスが多く発見されるのか
今回の取り組みには、訳抜け撲滅以外にも、「チェック工程の見直し」を行うという目的もありました。
必要な工程、不要な工程を見極める目的です。
こちらがチェック工程別のデータです。
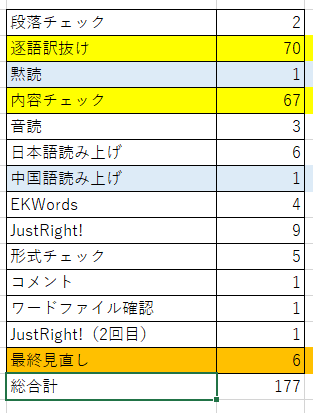
この表の上から順番にチェックしています。
ワードファイル確認というのは、調査結果や検索結果などをまとめたワードファイルに、未確定のものが混じっていたり、ペンディング案件がそのままになっていたりしないか確認するということです(「あとで確認」の印をつけています)。
チェックの肝となるのは、逐語訳抜けと内容チェックなので、この2つはどうしても多くなります。
あとは、「最終見直し」で6件というのは改めて多いなと感じます。
内容は、1件は「誤訳」判定、あとの5件は表現上の変更です。
ここでのミスの拾い上げはゼロにしないといけません。
今内容を見てみると、ちょっとしたものだったりするのですが、ずっと初めから悩みつつ最後になって変えたものもあります。
そして変えても変えなくても、どちらでもよいものもあります。
つまりは、決められない「引っ張り癖」がここに出ています。
これがチェックに時間がかかる原因にもなっているので、原則内容チェック終了後までには確定させるようにします。
逆にミス発見が少ないのは、黙読と中国語読み上げです。
中国語読み上げは、中国語をスマホアプリで読み上げてもらい日本語を見ながらチェックするものです。
ちなみに、TalkFreeというアプリを使っています。(Androidアプリです)
日本語も滑らかですが、中国語の滑らかさにはビビりますよ。
word読み上げ愛用者には悲しいお知らせですが、日本語もこちらの方が断然滑らかです。
これ、確かに「中国語を聞く」という負荷がかかるので、チェックとしては向いてないかなと思いつつ、違った視点でチェックできるのはいいかなと思い、取り入れていました。
ですが、ミスも拾えていないのでこの工程は一旦リストラします。
黙読も、このタイミングでは一旦省きます(最後の方でも登場するので)。
今後のミス対策
これまでの分析を踏まえて、今後のミス対策はこんな感じです。
- 引き続き記録を続ける
- 上記の対策は継続する。不要と判断した工程は一旦省く
- 訳抜けはまだあるので、引き続き傾向をつかみ対策を考える
- 最終見直しでのミスをゼロにするために、ミスが発生したら原因・対策を重点的に考える
少し具体性に欠けますね。ミスがないとなんとも対策がしづらいものもあります。
そういう意味でも、やはりミスは貴重です。
これだけはおすすめします
ここまでで、特に効果があったと思うことを最後にまとめます。
1.ミスしやすい部分を色分け
色はやはり、強力なツールだと思います。
ただし、Tradosに色つきで放り込むと、タグがついてしまうんですよね。このように。

Trados案件だと、適用が難しいのでは?と思います(すみません、やったことがないので推測です)。
私はTradosを使ってはいますが、Tradosで納品する案件ではないので今の所特に問題ないです。
2.EKWords+JustRight!の機械的チェック
EKWordsは揺らぎや、単語だけ抽出するので文章として見ていた時に気づけなかった違和感に気づくことがあります。
そしてJustRight!ですが、私はもうこれ、手放せないです。
安くないんですが、投資に見合うソフトだと思います。
間違えた所を登録していけば、(見落とさない限り)同じミスはなくなりますので、しっかり登録していくことでミスは収束していくと思っています。
3.ミスを記録する
エクセルに打ち込んだミスは、案件終了した際に打ち出して確認して、必要があればJustRight!などに登録していました。
今回ある程度のまとまった量のデータを見ていて、気づくこともありました。
ミスを記録するのは確かに手間ではありますが、あとで得られるものはかけた手間以上だと思いますのでおすすめです。
次の途中経過の際には、「訳抜けほぼゼロになりました!」と報告できるように、引き続き試行錯誤していきます。







